


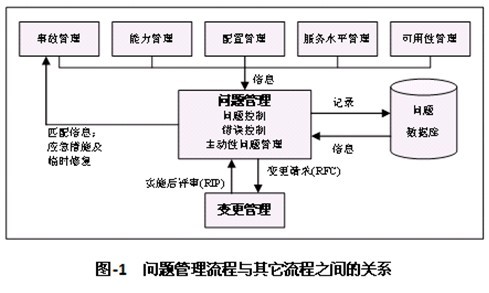
问题管理的主要活动有: 问题控制:定义、调查以及诊断;问题控制注重将问题转化成已知错误; 错误控制:监控并控制已知错误并提出变更请求(RFC);错误控制注重于通过变更管理过程在结构上解决已知错误;. 主动性问题管理:通过改进基础架构以及提出变更请求来阻止可避免事故的发生; 提供信息:对结果和重要问题的报告。
问题管理的输入有:
• 有关事故的详细信息,包括应急措施;
• 来自配置管理数据库(CMDB)的配置信息;
• 来自供应商的关于基础设施中使用的他们的产品的信息。这些信息包括技术细节和这些产品本身存在的已知错误;
• 服务目录和服务级别协议(SLA);
• 有关基础设施及其运行状况方面的信息,如能力记录、性能指标和服务级别报告等。
问题管理的输出包括:
• 一个已知错误数据库,它实际上是问题个数据库中的一部分;
• 变更请求(RFC);
• 最新的问题记录(主要更新与已知错误、解决方案和应急措施相关的信息);
• 一旦消除了事故发生的根源,就可以停止问题记录;
• 管理信息。
问题管理的主要活动有:
• 问题控制:定义、调查以及诊断;问题控制注重将问题转化成已知错误;
• 错误控制:监控并控制已知错误并提出变更请求(RFC);错误控制注重于通过变更管理过程在结构上解决已知错误;
• 主动性问题管理:通过改进基础架构以及提出变更请求来阻止可避免事故的发生;
• 提供信息:对结果和重要问题的报告。
1、问题控制
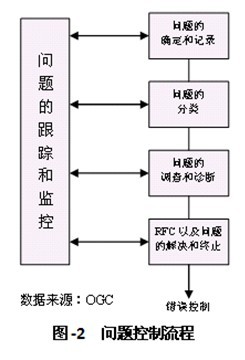
问题管理流程的第一项活动是问题控制。问题控制负责找出问题并调查其根源,其目标是通过确定问题根源并采取应急措施来把问题转化成已知错误。图-2描述了问题控制行为。
1.1 确认和记录问题
原则上讲,任何一个由未知原因引起的事故都与某个问题有关。然而,对问题的确认和记录只有当事故重复发生或有可能再次发生,或者发生了重大事故时才有意义。
“确认问题”这一活动通常由问题分析员完成,但是其它人员,如能力管理人员也可帮助对问题进行确认。
问题处理的细节与事故处理类似,但是在确定问题时没有必要包含用户相关信息。不过,必须确定与问题有关的事故,并找出他们与问题之间的关系。
那么如何确认一个问题呢?下面是一些例子:
• 对某一事故进行分析表明该事故是再次发生,而且有大量发生并且加重的趋势。
• 对基础架构进行分析可以找出可能会发生事故的薄弱环节(也可由可用性管理和能力管理来进行分析);
• 一个严重事故发生后应给予永久的予以解决,这样是为了避免下次再次发生这样的事故;
• 服务级别受到威胁(能力、性能、成本等);
• 记录下来的事故不能与一个现有的问题或已知错误进行关联。
趋势分析能够发现基础架构中一些需要进一步关注的环节。这些关注可从成本收益的角度进行分析,比如,通过确定基础架构中需要更多支持的地方以及这些地方与所提供的服务之间的关系等。
上述评估可基于问题的严重性或者说“痛苦指数”来完成。痛苦指数的确定可参考下列指标:
• 事故对业务活动带来的影响;
• 事故的数量;
• 受到影响的用户和业务流程数量;
• 解决事故的时间和成本。
1.2 问题的归类和分配
可以按照问题所处的区域和类别来对其进行分类。归类的第一步是进行影响度分析,即确定问题的严重程度及其对服务的影响程度(紧急度和影响度);然后与事故管理流程类似,设定问题的优先级;接着根据问题所处的类别分配人员和其它资源,并安排处理问题的时间。
对问题的归类可从以下几个方面进行:
• 类别 – 确定问题的性质,如是硬件方面的还是软件方面的;
• 影响度 – 主要指对业务流程的影响程度;
• 紧急度 – 在多长时间的解决是可接受的;
• 优先级 – 紧急度、影响、风险和所需资源等因素的综合考虑;
• 状态 – 如问题、已知错误、已解决、已终止但正在进行实施后评审等。
对问题的分类不是固定的,而是在问题的生命周期内可能发生变化的。例如,某一应急措施或者临时修复的存在可能会降低某一问题的紧急度和影响度,而新事故的影响度和紧急度却可能提高。1.3调查和诊断
调查与诊断是一个反复的过程——要重复进行多次,而每重复一次都更加接近我们想要的解决方案。通常,我们可能需要在测试环境中重现某一事故。这可能需要更多的专业人员的参与,比如说支持小组的专业人员可以协助进行问题的分析和诊断。
问题不一定完全由硬件和软件引起,文件错误或者人员和程序方面的错误如软件版本发布不当等都可能导致问题。因此,将问题处理程序归入配置管理数据库(CMDB)并对其进行版本控制是非常有益的。当然就一般情况而言,大部分错误还是与基础架构的组件相关的。
一旦找到问题的根源以及与此问题相关的一个或多个配置项,就可建立配置项和相应事故之间的关联;之后如果找到了解决此问题的应急措施,此问题就转变为已知错误。然后,问题管理流程错误控制和问题控制活动阶段。
1.4临时修复
在解决问题的过程中,如果问题导致了严重的事故,那么找到一个临时修复或紧急修复的方法是非常必要的。但是如果临时修复需要对基础架构进行一些改动,那么必须首先提交变更请求(RFC)(这主要是指在找到问题的最终原因之前)。如果特别严重而且不容耽搁,就必须启动紧急变更请求处理程序。
2、错误控制
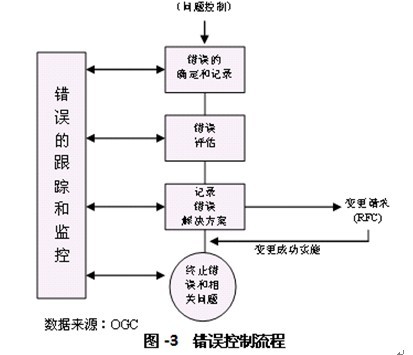
错误控制指监控和管理已知错误直到其尽可能地得到适当的处理。为此,它需要向变更管理提交变更请求(RFC),并在实施变更后对变更进行实施后评审以评估其效果。错误控制对已知错误从被确认到被解决的整个生命周期进行监控,在此过程中它可能会涉及公司的多个部门,包括生产和开发部门。
2.1错误确认和记录
一旦找到问题的根源和与此问题相关联的配置项,以及解处理它的应急措施,就可将其状态转变为“已知错误”或者与某个现有的已知错误相关联。然后就可以开始进行错误控制。如果此时仍有未解决的事故,问题管理可将问题解决情况告知事故管理以便他们解决还未解决的事故。
2.2错误评估和解决方案评估
参与问题管理的人员评估解决问题和已知错误(在找到问题的根因之后)时所需资源。他们根据服务级别协议(SLA)、处理事故和已知错误所需成本和所可能获得的收益、变更请求(RFC)的影响度和紧急度等因素来比较不同的解决方案。解决问题(或已知错误)的所有活动都应该加以记录以便对其进行监控和确定它们不同时期的状态。
2.3确定解决方案和记录解决方案的实施情况
问题管理流程需要最终确定对问题的最合适的解决方案,包括确定是需要临时性修复措施还是永久性解决方案,或者两者皆需要。甚至,它也可能决定不修复此问题,比如是考虑到这样做从业务上来看并不划算。举例来说,一个公司自己开发的ERP系统出现故障,但是由于公司已经决定年底采用SAP的产品,因此可能并不会对现有系统源代码进行修改,因为在此情况或与此类似的情况下,修复它的成本将超出所能获得的利益。
虽然在大部分情况下,解决问题的成本是可接受的,并且可以通过解决问题很容易地终止与此问题有关的事故,但是在某些情况下解决问题和与其相关的事故需要耗费过多的精力。
但不管最终决定是什么,与已知错误有关的信息应该进行记录并可供事故管理流程使用。
一旦确定了合适的解决方案,就有了足够的信息来提交变更请求(RFC)。然后,变更管理就开始通过变更请求(RFC)来负责解决方案的实际执行。
2.4 来自于其它环境的故障根源
大部分情况下,我们只找出存在于运营环节中的故障,但其实产品在进入运营环节之前-即开发环境(外部供应商或内部开发单位)中-即已存在故障和已知错误(缺陷)。(对开发部门来说,软件开发环境即是他们的运营环境)
正常情况下,开发者和供应商会指出包含在其产品中的错误,互联网站和专业杂志也会提供一些常用产品的缺陷方面的信息,此外,有些厂商也会提供存有其产品存在的已知错误的数据库。
如果在所提供的产品中存在的已知错误并不是非常严重而且有可合适的应急措施可用采用,或者由于业务方面的某些原因而不得不采用某些有缺陷的产品,就可能会在运营环境中使用本应处于开发环境中的产品,此时在错误控制中包括已知错误和相关应急措施是非常有必要的。
同时,还可以将此错误与问题管理流程进行关联以便在实施包含该错误的产品过程中能够及时发现这些错误。
此外,在开始实施某个产品或方案之前,变更管理需要决定包含在这些产品或方案中的已知错误是否是可以接受的。如果不能接受,则需决定是否否决该项实施。在这种情况下,变更管理最初决定通常需要承担一定的压力,因为用户正在等着新的功能的实现。
2.5实施后评审(PIR)
用于解决问题、已知错误及相关事故的变更一旦实施后,在终止有关记录工作之前必须对变更进行实施后评审(Post-Implementation Review,PIR)。如果变更成功实施,那么对所有问题和已知错误及相关事故的记录工作都可以终止了。而对一个问题记录来说,其在问题数据库中的状态会被置成“已解决”。事故管理将被告知对与事故相关的问题也可以终止了。对重大问题来说,完成实施后评审之后还要另外执行重大问题评审,这是为了了解:
• 什么工作做得好;
• 什么工作做得不好;
• 下次我们怎么样才能做得更好;
• 我们怎么样才能防止故障的再次发生。
需要提示的是:许多公司进行实施后评审是为了确保与问题相关的所有事故终止(包括确认客户是否同意终止事故)之后才能终止此问题。如果与其相关的所有事故没有全部终止,则需将该问题重新置为“未解决”状态。2.6跟踪与监控
该活动负责在问题和已知错误的整个生命周期内对他们的发展情况进行监控。这些工作在问题控制和错误控制中都要实施。这样做的目的是:• 确定变更的影响度和紧急度,并在必要的时候调整现有的优先级;
• 监控对问题和已知错误的诊断进展情况和方案实施情况,同时监控变更请求(RFC)的执行情况。因此,变更管理会经常性地告知问题管理流程其提交的变更请求(RFC)的处理进展。
3、主动问题管理
总体来说,主动问题管理(指防止问题的发生)关注的是服务和基础架构的质量。它注重分析基础架构的运行趋势并找出哪些潜在事故以防止其发生。为此,主动问题管理需要找出基础架构中的薄弱环节或超负荷工作的组件。
如果查找的范围包括若干领域,那么对某一领域内为防止问题发生而做的努力也必须在其它领域内实施。可以对基础架构中的薄弱环节进行确定并对其进行调查研究。
4、提供信息
在问题管理流程中,一些与应急措施和临时修复相关的信息会提供给事故管理流程。这样,服务台可以通知任何受到影响的用户。问题管理利用配置管理数据库(CMDB)和服务级别协议(SLA)来确定应该通知何人何种信息。


京ICP备06004481号 Copyright 2002 - 2006 ITGov.org.cn, All Rights Reserved